Some statistical jobs are either too memory-greedy or computationally intensive to run on a local machine. At the Johns Hopkins Medical Institutes (JHMI), researchers have access to a Linux cluster running a Oracle Grid Enginge (previously called the Sun Grid Engine).
Jobs on the Joint HPC Exchange (JHPCE) can be run interactively with the qrsh command or through a qsub bash submission. JHPCE also has Stata-MP installed so that’s another reason why I use it for larger jobs.
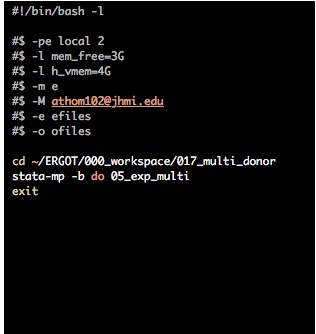
I usually submit a qsub job by writing qsub Scripts/NAME_OF_SCRIPT into terminal. All of my scripts are kept in the Scripts directory and usually named with the convention run<PROJECT>_<DO>.sh or run017_05.sh for a Stata bash file to run do file 05 in the 017 project (I explain my project organization in another post). The command qsub Scripts/run017_05.sh will read the follow script.
#!/bin/bash -l
#$ -pe local 2
#$ -l mem_free=3G
#$ -l h_vmem=4G
#$ -m e
#$ -M alvin@jhmi.edu
#$ -e efiles
#$ -o ofiles
cd ~/ERGOT/000_workspace/017_multi_donor
stata-mp -b do 05_exp_multi
exit
The line -pe local 2 tells the cluster that I’ll need two computing cores. For JHPCE users - our current license only allows for 2-cores so there’s no benefit to requesting more.
The lines -l mem_free=3G and h_vmem=4G tells the cluster that I need 3G of memory allocated to this job. If Stata starts requesting more that 4G, then the job will be aborted. Stata-MP tends to benefit more from computing cores than RAM, so I generally keep these requests low (I often don’t go over 1G of actual use). R, on the otherhand, is memory-greedy so I sometimes request 10-20G of memory for complex jobs.
The next two lines, -m -e and -M alvin@jhmi.edu tell the cluster to send me an email when the job is done. I wouldn’t use this line if you’re submitting tons of jobs at once, but it’s useful for those one-off jobs that will take hours to complete.
The next two lines, -e efiles and -o ofiles tells qsub to put error files in the efiles directory (located at ~/efiles) and output files in the ofiles directory (located at ~/ofiles).
Finally, we get to the actual Stata part. First I change to the working directory with the cd command. Then I run bash stata using stata-mp -b - note that you could also write stata-se -b or stata -b if you don’t want to use Stata-MP. On the same line I submit the stata command do and the name of the do file. After that runs we’ll exit Stata with exit.
Here’s a gist.
comments powered by Disqus